웹마스터 팁
PHP 혼자 공부하기 - 11 :: 정규식 실전예제
2003.04.16 14:58
이번 강의가 벌써 정규식 세번째 강의입니다. 하나로 너무 우려먹는 것 같다고 생각하지 말아주세요. 제가 정규식을 모르던 시절, 좀 안다는 친구한테 정규식에 대해서 물어봤다가 설움당했던 걸 생각하면...ㅠ_ㅠ 알고나니 이렇게 편하고 좋은 것을 그 때는 왜 그렇게 머리에 안들어오던지... 사실 정규식에 대해서 제대로 된 강의가 없다는 것이 핑계라면 핑계였습니다. 그래서~~ ^^ 저는 군더더기를 뺀 실전 정규식만 강의하려합니다. 근데 이거 끝나고 나면 다음주제는 뭐로 할까요? 아직 정해놓은 것이 없다는...
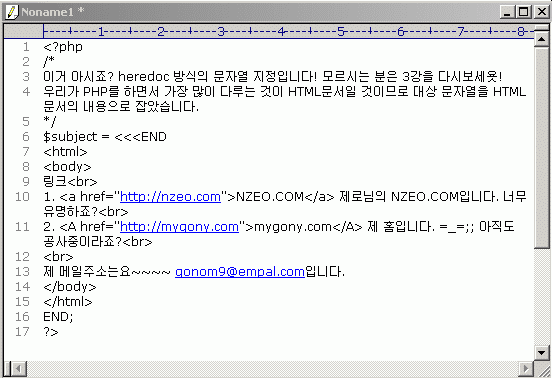
우선 정규식을 공부하기 위한 소스로 다음과 같이 문자열을 작성합니다. 아래에 실전으로 하는 소스들은 모두 이 문자열을 바탕으로 실습해 볼 것이므로 문자열을 지정한 곳 아래에 정규식 사용의 소스를 넣어주시면 됩니다.
1. 가장 기초적인 형태의 정규식
자... 실전강의에 들어갑니다. 아! 이 강의를 보시기 전에 기존의 정규식 강의 두개도 함께 펼쳐놓고 번갈아 가면서 보는 것을 잊으시면 안됩니다.
위의 주소에서 우선 가장 간단한 형태로 "메일" 이라는 단어의 존재 유무를 판별해봅니다. 정규식은 만들기 전에 그것으로 무엇을 먼저 할 것인가, 그리고 어떤 것들을 뽑아낼 것인가를 잘 생각하셔야 합니다. 정규식 함수부분에서 이미 "존재 유무"를 판별하는 함수에 대해서 배운 적이 있습니다. 바로 preg_match 죠~ ^^;
당연히 결과는 1입니다. 눈으로도 보이지만 분명히 대상 문자열에는 "메일"이라는 단어가 있거든요. 그럼 슬래시가 있는지 찾아보도록 할까요? 슬래시(/)는 구획문자로 지정이 되어있기 때문에 메타문자의 역할을 합니다. 따라서, 슬래시를 찾기 위해서는 메타문자로서의 효력을 잃게 하는 방법 - 즉 구획문자를 다른 문자로 대체해버리는 방법이 있고, 혹은 이스케이프 문자()를 붙여서 일반 문자로 인식하게 하는 방법이 있죠. 두가지 경우에 대해서 작성해보도록 하세요.
이번에는 조금 더 복잡하게 해서... 물음표의 갯수를 찾습니다.
소스가 간단하니까 이해가 쉽게 되실거예요. $match에 대해서는 아직 신경쓰지 마세요.
자... 그 다음은 구분자를 사용해보도록 하죠. 본문중 nzeo.com의 숫자를 세는 겁니다. 음... 1개밖에 안 보이네요. 그럼 대소문자를 구분하지 않으면?
2. 서브 패턴의 활용
그럼 이번에는 서브패턴이라는 넘을 사용해봅니다. 서브 패턴은 괄호 () 로 묶어 주는 부분을 말하는 것으로, 이 부분만 따로 추려내고자 할 때에도 사용될 수 있습니다.
예로, 링크 걸린 URL들을 뽑아와봅니다. 우선, 규칙을 생각해야 되는데, 소스에 보면, a href="URL" 이라는 형태로 URL들이 링크되어있습니다. 그쵸? ^^
여기에서 쓰인 정규식 패턴은 /a href="(.+)"/i 입니다. 어떤 의미인지 살펴보도록 하겠습니다. 우선 구분자 i가 눈에 띄이죠? 당연히 대소문자 구별을 안하기 위해서입니다. 그 다음에 눈에 띄는 것이 " 일텐데 당연히 문자열 속에 큰따옴표를 쓰기 위해서 이스케이프 시켜준 것입니다. 그 다음은 단연 (.+) 부분이 눈에 띄이죠? ()는 서브 패턴으로 나중에 어떤 것들이 패턴에 일치하는지 알아보기 위함인데, 뒷 부분에 설명드리기로 하고, .+ 부터 살펴보자면, 도트(.)는 s 옵션이 없을 때에는 개행문자를 제외한 모든 문자를 의미하는 메타문자라고 했고, 플러스 기호(+)는 바로 앞 패턴 혹은 문자가 1개 이상있다는 의미라고 그랬습니다. 즉, .+의 의미는 개행문자를 제외한 모든 문자가 1개 이상 있다는 의미가 되겠습니다. 그리고 이것을 괄호로 묶었죠. 이제부터 거기에 대해서 설명을 드립니다.
preg_ 계열의 함수의 변수 중 $match 혹은 $matches 라고 되어있는 부분들은 전부 저러한 서브 패턴들을 받아오기 위해서라고 보시면 됩니다. 저 소스 다음에 다음 부분을 추가해보세요.
차이가 보이시죠? 그럼, 같은 방식으로 다음 소스를 추가해보세요.
나온 부분이 어디인지 짐작이 가시나요? 바로 (.+)에 해당하는 부분입니다! 만약 패턴안에 괄호가 또 있다면 괄호의 순서대로 1번 2번 3번...의 순서를 가지게 됩니다. 저렇게 2차원배열 표현되는 이유는 preg_match_all 함수가 각각의 경우에 대해서 배열을 가지고 있기 때문입니다. 즉, 다음과 같이 됩니다.
패턴에 일치한 전체 문자열 -> $match[0] 에 저장되고,
패턴에 일치한 문자열 중 첫번째 서브패턴 -> $match[1]에 저장됩니다.
단, preg_match_all 이 모든 경우를 조사하게 되어있는 함수이므로,
패턴에 일치한 첫번째 전체 문자열 -> $match[0][0]에 저장되고,
패턴에 일치한 두번째 전체 문자열 -> $match[0][1]에 저장됩니다.
preg_match의 경우라면 하나만 검사하게 되니까 $match[0] 과 $match[1] 은 배열이 아니게 됩니다. 즉, $match[0]과 $match[1]의 값을 바로 쓸 수 있다는 것이죠. 위의 소스에서 preg_match_all을 preg_match 의 경우로 바꾸어서 실험해보세요.
그럼 이번에는 메일주소를 패턴으로 만들어봅시다.
우선, 일반적인 메일주소의 규칙에 관해서 생각해보면...
1. 아이디는 한개이상의 영문자, 숫자, 언더스코어(_), 하이픈(-) 으로 이루어져있다.
2. 아이디뒤에는 반드시 골뱅이(@) 가 붙는다.
3. 골뱅이 뒤에 오는 도메인은 한개이상의 영문자, 숫자, 언더스코어, 하이픈 그리고 도트(.)로 구성된다.
규칙들을 차근차근따져가면서 하도록 할께요. ^^
우선, 허용하는 문자들의 범위에 대해서 생각해보면 영문자 숫자, 언더스코어, 하이픈입니다. 이것들로 문자범위를 지정해줄 건데 그 중 하이픈은 메타문자로군요. 따라서 하이픈에만 이스케이프 문자()를 붙여주고 나머지는 범위로 지정하도록 합니다.
[a-zA-Z0-9_-]
허용하는 문자의 범위는 a부터 z까지, A부터 Z까지 0부터 9까지 그리고 언더스코어와 하이픈입니다. 왜 a-Z라고 하지 않는지는 아스키 코드표를 보시면 이해하시리라고 생각합니다. ^^ 문자의 범위는 그렇게 나누었지만, 이 문자들은 반드시 1개 이상이어야 합니다. 없어서는 안되고 없을 수도 없는 값이죠. 따라서...
[a-zA-Z0-9_-]+
와 같은 패턴이 나옵니다. 만약에 "메일주소의 아이디는 반드시 3글자 이상이어야 한다."는 규칙을 세웠다면 어떻게 될까요? 문자의 갯수를 지정하는 메타문자로 중괄호 {} 가 있었습니다. 만약 3글자 이상이라는 규칙을 따르려면
[a-zA-Z0-9_-]{3}
으로 적어주시면 되고, 3글자 이상 8글자이하 라는 규칙은
[a-zA-Z0-9_-]{3,8}
로 표현합니다. 이제 중괄호의 쓰임도 아시겠죠? 사실 + 라는 것은 {1} 과 같은 의미입니다. *도 {0}과 같은 의미이구요. ^^;;
그 다음에는 골뱅이를 넣어야 합니다. 골뱅이는 메타문자가 아닌 관계로 그냥 써주시면 되고, 그 다음은 도메인의 규칙인데... 도메인의 규칙을 잘 살펴보시면...
[a-zA-Z0-9_.-]+
정도는 생각해낼 수 있으실 겁니다. 물론, 조금만 더 깊게 생각한다면 도메인 명이 최소 3글자 이상이여야 한다는 사실도 알 수 있죠. ^^;; 이유는 곰곰히 생각해보세요.
자... 이제 패턴이 완성되었습니다.
/[a-zA-Z0-9_-]+@[a-zA-Z0-9_.-]{3}/
완성된 패턴입니다. 여기서 서브패턴을 추가해보자면... 골뱅이를 중심으로 나누어져있는 아이디와 도메인을 가져와보도록 하겠습니다.
/([a-zA-Z0-9_-]+)@([a-zA-Z0-9_.-]{3})/
이 패턴으로 preg_match 함수를 써보세요. $match[0] 에는 메일주소 전체가, $match[1]에는 첫번째 서브패턴에 해당하는 아이디가, $match[2]에는 두번째 서브패턴에 해당하는 도메인이 각각 저장됩니다. 만약 도메인 중에서 hanmail.net 과 daum.net 의 주소만 골라내려면? OR 의 의미를 가지는 메타문자 찾아보고 계시나요? 저번 강의중에 있던 내용입니다. ^^
결론은 간단하게...
/([a-zA-Z0-9_-]+)@(hanmail.net|daum.net)/
입니다. OR의 의미를 가지는 메타문자(|)를 중간에 써주면 "hanmail.net 혹은 daum.net" 이라는 의미가 됩니다.
이번에는 도메인 패턴을 작성해봅니다. 먼저 규칙을 생각해보면...
1. 도메인 앞부분에 "http://" 가 붙을 수도 있고, 그렇지 않을 수도 있다.
2. 도메인은 한개이상의 영문자, 숫자, 언더스코어, 하이픈 그리고 도트(.)로 구성된다.
메일 주소를 찾아낼 때 했던 것이기 때문에 당연히 더 간단하게 할 수 있습니다. 버뜨... 우리가 할 것은... 도메인을 찾아서 도메인 앞에 http:// 가 없으면 붙여주는 정규식 패턴과 함수를 작성할 것입니다. 우선 패턴부터 만들어봅니다.
/(http://)?([a-zA-Z0-9_-]+.[a-zA-Z0-9_.-]+)/
이렇게 될 수 있겠죠? 머... 스스로 읽을 줄 알 것이라고 생각하지만... 이것까지는 분석해보도록 합니다.
(http://)?
물음표의 의미를 모르시겠다면 정규식 패턴 문법 부분을 다시 보시기를 바랍니다. 중괄호로 표현하자면 {0,1} 쯤 됩니다.
도메인 부분에서는 지정된 문자와 점을 포함하는 문자를 도메인으로 인식하도록 했습니다. 대괄호 [] 속의문자는 그 문자들을 "허용"한다는 것이지 반드시 있어야 한다라는 의미는 못되거든요. 따라서 점을 반드시 포함시키기 위해서는 대괄호 밖으로 빼낼 필요가 있었습니다.
당연히 반환되는 값이야 1이겠지만 그게 중요한게 아니라 우리가 볼 것은 $match[1]의 값. 즉, http:// 가 있는지 없는지가 중요합니다. 만약 있다면 그대로 놔두고 없다면 http://를 붙여줘야겠죠. 이럴 때 사용하는 함수가 바로 preg_replace_callback 입니다. 정규식을 통해 동적으로 치환을 하는 강력한 함수죠.
아주 간단한 형태의 preg_replace_callback 함수 사용법이었습니당. ^^
자.. 그러면 이번에는 preg_replace 를 이용해서 a 태그 사이에 있는 문자열만 뽑아서 a 태그를 없애버리는 겁니다.
그럴려면 우선 a태그의 특성을 알아야 합니다.
1. 시작부분은 "<a"로 시작하고 >로 끝을 맺는다.
2. 시작과 끝 태그 사이에는 어떤 문자라도 올 수 있다.
3. 끝 부분은 "" 이다.
4. 태그는 대소문자를 구분하지 않는다.
규칙이 완성되었습니다. 규칙에 의해서 정규식 패턴을 작성해보면...
/<a(.*)>(.*)</a>/is
와 같이 나타나게 됩니다. ^^;; preg_replace 함수의 사용법은 대강 보셨죠?
^^ preg_replace 함수에 보면 replacement 라고 정의된 부분이 있는데 이 부분이 치환할 문자열을 저장하는 곳입니다. 그리고 $숫자 의 형태로 위에서의 $match[1] 과 같은 내용을 받아옵니다. 즉, preg_match에서의 $match[숫자]의 형태가 preg_replace에서는 $숫자 의 형태로 변환될 수 있습니다. 그렇지만 일반 문자열에서 달러문자($)는 메타문자의 성격을 지니기 때문에 이스케이프 문자()를 붙여줘야 합니다.
즉, 위의 소스는 조건을 만족하는 문자열을 태그를 제외한 나머지 부분만으로 치환시켜 버린다는 거죠. ^^;;
이걸로 대강 정규식에 대한 이해가 되었나요? 가능하면 쉽게 풀어쓰려고 했지만, 원래 어렵기도 하고 또 저도 시간에 쫓기다 보니 쉽지만은 않았네요. 더욱 더 고급응용을 하게 되면 템플릿을 만든다거나 하는 고급 활용도 가능하지만 이 부분은 접고 다른 걸 하도록 하죠.
원하시는 강의가 있으면 리플로 어택해주세요~ ^^
### 생각해볼 문제
야후 사이트 첫페이지에...
1. 사용된 a태그는 전부 몇 개일까요?
2. a 태그안에 사용된 URL만을 뽑아서 전부 출력해보세요.
3. 태그가 아닌 영문자 5글자 이상으로 이루어진 단어는 어떤 것들이 있는가?
우선 정규식을 공부하기 위한 소스로 다음과 같이 문자열을 작성합니다. 아래에 실전으로 하는 소스들은 모두 이 문자열을 바탕으로 실습해 볼 것이므로 문자열을 지정한 곳 아래에 정규식 사용의 소스를 넣어주시면 됩니다.
1. 가장 기초적인 형태의 정규식
자... 실전강의에 들어갑니다. 아! 이 강의를 보시기 전에 기존의 정규식 강의 두개도 함께 펼쳐놓고 번갈아 가면서 보는 것을 잊으시면 안됩니다.
위의 주소에서 우선 가장 간단한 형태로 "메일" 이라는 단어의 존재 유무를 판별해봅니다. 정규식은 만들기 전에 그것으로 무엇을 먼저 할 것인가, 그리고 어떤 것들을 뽑아낼 것인가를 잘 생각하셔야 합니다. 정규식 함수부분에서 이미 "존재 유무"를 판별하는 함수에 대해서 배운 적이 있습니다. 바로 preg_match 죠~ ^^;
echo preg_match("/메일/", $subject);
당연히 결과는 1입니다. 눈으로도 보이지만 분명히 대상 문자열에는 "메일"이라는 단어가 있거든요. 그럼 슬래시가 있는지 찾아보도록 할까요? 슬래시(/)는 구획문자로 지정이 되어있기 때문에 메타문자의 역할을 합니다. 따라서, 슬래시를 찾기 위해서는 메타문자로서의 효력을 잃게 하는 방법 - 즉 구획문자를 다른 문자로 대체해버리는 방법이 있고, 혹은 이스케이프 문자()를 붙여서 일반 문자로 인식하게 하는 방법이 있죠. 두가지 경우에 대해서 작성해보도록 하세요.
이번에는 조금 더 복잡하게 해서... 물음표의 갯수를 찾습니다.
echo preg_match_all("/?/", $subject, $match);
소스가 간단하니까 이해가 쉽게 되실거예요. $match에 대해서는 아직 신경쓰지 마세요.
자... 그 다음은 구분자를 사용해보도록 하죠. 본문중 nzeo.com의 숫자를 세는 겁니다. 음... 1개밖에 안 보이네요. 그럼 대소문자를 구분하지 않으면?
소스1.
echo preg_match_all("/nzeo.com/", $subject, $match);
소스2.
echo preg_match_all("/nzeo.com/i", $subject, $match);
echo preg_match_all("/nzeo.com/", $subject, $match);
소스2.
echo preg_match_all("/nzeo.com/i", $subject, $match);
2. 서브 패턴의 활용
그럼 이번에는 서브패턴이라는 넘을 사용해봅니다. 서브 패턴은 괄호 () 로 묶어 주는 부분을 말하는 것으로, 이 부분만 따로 추려내고자 할 때에도 사용될 수 있습니다.
예로, 링크 걸린 URL들을 뽑아와봅니다. 우선, 규칙을 생각해야 되는데, 소스에 보면, a href="URL" 이라는 형태로 URL들이 링크되어있습니다. 그쵸? ^^
echo preg_match_all("/a href="(.+)"/i", $subject, $match);
여기에서 쓰인 정규식 패턴은 /a href="(.+)"/i 입니다. 어떤 의미인지 살펴보도록 하겠습니다. 우선 구분자 i가 눈에 띄이죠? 당연히 대소문자 구별을 안하기 위해서입니다. 그 다음에 눈에 띄는 것이 " 일텐데 당연히 문자열 속에 큰따옴표를 쓰기 위해서 이스케이프 시켜준 것입니다. 그 다음은 단연 (.+) 부분이 눈에 띄이죠? ()는 서브 패턴으로 나중에 어떤 것들이 패턴에 일치하는지 알아보기 위함인데, 뒷 부분에 설명드리기로 하고, .+ 부터 살펴보자면, 도트(.)는 s 옵션이 없을 때에는 개행문자를 제외한 모든 문자를 의미하는 메타문자라고 했고, 플러스 기호(+)는 바로 앞 패턴 혹은 문자가 1개 이상있다는 의미라고 그랬습니다. 즉, .+의 의미는 개행문자를 제외한 모든 문자가 1개 이상 있다는 의미가 되겠습니다. 그리고 이것을 괄호로 묶었죠. 이제부터 거기에 대해서 설명을 드립니다.
preg_ 계열의 함수의 변수 중 $match 혹은 $matches 라고 되어있는 부분들은 전부 저러한 서브 패턴들을 받아오기 위해서라고 보시면 됩니다. 저 소스 다음에 다음 부분을 추가해보세요.
echo $match[0][0];
차이가 보이시죠? 그럼, 같은 방식으로 다음 소스를 추가해보세요.
echo $match[1][0];
나온 부분이 어디인지 짐작이 가시나요? 바로 (.+)에 해당하는 부분입니다! 만약 패턴안에 괄호가 또 있다면 괄호의 순서대로 1번 2번 3번...의 순서를 가지게 됩니다. 저렇게 2차원배열 표현되는 이유는 preg_match_all 함수가 각각의 경우에 대해서 배열을 가지고 있기 때문입니다. 즉, 다음과 같이 됩니다.
패턴에 일치한 전체 문자열 -> $match[0] 에 저장되고,
패턴에 일치한 문자열 중 첫번째 서브패턴 -> $match[1]에 저장됩니다.
단, preg_match_all 이 모든 경우를 조사하게 되어있는 함수이므로,
패턴에 일치한 첫번째 전체 문자열 -> $match[0][0]에 저장되고,
패턴에 일치한 두번째 전체 문자열 -> $match[0][1]에 저장됩니다.
preg_match의 경우라면 하나만 검사하게 되니까 $match[0] 과 $match[1] 은 배열이 아니게 됩니다. 즉, $match[0]과 $match[1]의 값을 바로 쓸 수 있다는 것이죠. 위의 소스에서 preg_match_all을 preg_match 의 경우로 바꾸어서 실험해보세요.
그럼 이번에는 메일주소를 패턴으로 만들어봅시다.
우선, 일반적인 메일주소의 규칙에 관해서 생각해보면...
1. 아이디는 한개이상의 영문자, 숫자, 언더스코어(_), 하이픈(-) 으로 이루어져있다.
2. 아이디뒤에는 반드시 골뱅이(@) 가 붙는다.
3. 골뱅이 뒤에 오는 도메인은 한개이상의 영문자, 숫자, 언더스코어, 하이픈 그리고 도트(.)로 구성된다.
규칙들을 차근차근따져가면서 하도록 할께요. ^^
우선, 허용하는 문자들의 범위에 대해서 생각해보면 영문자 숫자, 언더스코어, 하이픈입니다. 이것들로 문자범위를 지정해줄 건데 그 중 하이픈은 메타문자로군요. 따라서 하이픈에만 이스케이프 문자()를 붙여주고 나머지는 범위로 지정하도록 합니다.
[a-zA-Z0-9_-]
허용하는 문자의 범위는 a부터 z까지, A부터 Z까지 0부터 9까지 그리고 언더스코어와 하이픈입니다. 왜 a-Z라고 하지 않는지는 아스키 코드표를 보시면 이해하시리라고 생각합니다. ^^ 문자의 범위는 그렇게 나누었지만, 이 문자들은 반드시 1개 이상이어야 합니다. 없어서는 안되고 없을 수도 없는 값이죠. 따라서...
[a-zA-Z0-9_-]+
와 같은 패턴이 나옵니다. 만약에 "메일주소의 아이디는 반드시 3글자 이상이어야 한다."는 규칙을 세웠다면 어떻게 될까요? 문자의 갯수를 지정하는 메타문자로 중괄호 {} 가 있었습니다. 만약 3글자 이상이라는 규칙을 따르려면
[a-zA-Z0-9_-]{3}
으로 적어주시면 되고, 3글자 이상 8글자이하 라는 규칙은
[a-zA-Z0-9_-]{3,8}
로 표현합니다. 이제 중괄호의 쓰임도 아시겠죠? 사실 + 라는 것은 {1} 과 같은 의미입니다. *도 {0}과 같은 의미이구요. ^^;;
그 다음에는 골뱅이를 넣어야 합니다. 골뱅이는 메타문자가 아닌 관계로 그냥 써주시면 되고, 그 다음은 도메인의 규칙인데... 도메인의 규칙을 잘 살펴보시면...
[a-zA-Z0-9_.-]+
정도는 생각해낼 수 있으실 겁니다. 물론, 조금만 더 깊게 생각한다면 도메인 명이 최소 3글자 이상이여야 한다는 사실도 알 수 있죠. ^^;; 이유는 곰곰히 생각해보세요.
자... 이제 패턴이 완성되었습니다.
/[a-zA-Z0-9_-]+@[a-zA-Z0-9_.-]{3}/
완성된 패턴입니다. 여기서 서브패턴을 추가해보자면... 골뱅이를 중심으로 나누어져있는 아이디와 도메인을 가져와보도록 하겠습니다.
/([a-zA-Z0-9_-]+)@([a-zA-Z0-9_.-]{3})/
이 패턴으로 preg_match 함수를 써보세요. $match[0] 에는 메일주소 전체가, $match[1]에는 첫번째 서브패턴에 해당하는 아이디가, $match[2]에는 두번째 서브패턴에 해당하는 도메인이 각각 저장됩니다. 만약 도메인 중에서 hanmail.net 과 daum.net 의 주소만 골라내려면? OR 의 의미를 가지는 메타문자 찾아보고 계시나요? 저번 강의중에 있던 내용입니다. ^^
결론은 간단하게...
/([a-zA-Z0-9_-]+)@(hanmail.net|daum.net)/
입니다. OR의 의미를 가지는 메타문자(|)를 중간에 써주면 "hanmail.net 혹은 daum.net" 이라는 의미가 됩니다.
이번에는 도메인 패턴을 작성해봅니다. 먼저 규칙을 생각해보면...
1. 도메인 앞부분에 "http://" 가 붙을 수도 있고, 그렇지 않을 수도 있다.
2. 도메인은 한개이상의 영문자, 숫자, 언더스코어, 하이픈 그리고 도트(.)로 구성된다.
메일 주소를 찾아낼 때 했던 것이기 때문에 당연히 더 간단하게 할 수 있습니다. 버뜨... 우리가 할 것은... 도메인을 찾아서 도메인 앞에 http:// 가 없으면 붙여주는 정규식 패턴과 함수를 작성할 것입니다. 우선 패턴부터 만들어봅니다.
/(http://)?([a-zA-Z0-9_-]+.[a-zA-Z0-9_.-]+)/
이렇게 될 수 있겠죠? 머... 스스로 읽을 줄 알 것이라고 생각하지만... 이것까지는 분석해보도록 합니다.
(http://)?
물음표의 의미를 모르시겠다면 정규식 패턴 문법 부분을 다시 보시기를 바랍니다. 중괄호로 표현하자면 {0,1} 쯤 됩니다.
도메인 부분에서는 지정된 문자와 점을 포함하는 문자를 도메인으로 인식하도록 했습니다. 대괄호 [] 속의문자는 그 문자들을 "허용"한다는 것이지 반드시 있어야 한다라는 의미는 못되거든요. 따라서 점을 반드시 포함시키기 위해서는 대괄호 밖으로 빼낼 필요가 있었습니다.
preg_match("/(http://)?([a-zA-Z0-9_-]+.[a-zA-Z0-9_.-]+)/ ", $subject, $match);
당연히 반환되는 값이야 1이겠지만 그게 중요한게 아니라 우리가 볼 것은 $match[1]의 값. 즉, http:// 가 있는지 없는지가 중요합니다. 만약 있다면 그대로 놔두고 없다면 http://를 붙여줘야겠죠. 이럴 때 사용하는 함수가 바로 preg_replace_callback 입니다. 정규식을 통해 동적으로 치환을 하는 강력한 함수죠.
<?php
$subject = ~~~ 생략
$pattern = "/(http://)?([a-zA-Z0-9_-]+.[a-zA-Z0-9_.-]+)/i";
echo preg_replace_callback($pattern, "callback_func", $subject);
function callback_func($input){
...if(!$input[1]){
......return "http://".$input[0];
...}
}
?>
$subject = ~~~ 생략
$pattern = "/(http://)?([a-zA-Z0-9_-]+.[a-zA-Z0-9_.-]+)/i";
echo preg_replace_callback($pattern, "callback_func", $subject);
function callback_func($input){
...if(!$input[1]){
......return "http://".$input[0];
...}
}
?>
아주 간단한 형태의 preg_replace_callback 함수 사용법이었습니당. ^^
자.. 그러면 이번에는 preg_replace 를 이용해서 a 태그 사이에 있는 문자열만 뽑아서 a 태그를 없애버리는 겁니다.
그럴려면 우선 a태그의 특성을 알아야 합니다.
1. 시작부분은 "<a"로 시작하고 >로 끝을 맺는다.
2. 시작과 끝 태그 사이에는 어떤 문자라도 올 수 있다.
3. 끝 부분은 "" 이다.
4. 태그는 대소문자를 구분하지 않는다.
규칙이 완성되었습니다. 규칙에 의해서 정규식 패턴을 작성해보면...
/<a(.*)>(.*)</a>/is
와 같이 나타나게 됩니다. ^^;; preg_replace 함수의 사용법은 대강 보셨죠?
preg_replace("/<a(.*)>(.*)</a>/is", "$2", $subject);
^^ preg_replace 함수에 보면 replacement 라고 정의된 부분이 있는데 이 부분이 치환할 문자열을 저장하는 곳입니다. 그리고 $숫자 의 형태로 위에서의 $match[1] 과 같은 내용을 받아옵니다. 즉, preg_match에서의 $match[숫자]의 형태가 preg_replace에서는 $숫자 의 형태로 변환될 수 있습니다. 그렇지만 일반 문자열에서 달러문자($)는 메타문자의 성격을 지니기 때문에 이스케이프 문자()를 붙여줘야 합니다.
즉, 위의 소스는 조건을 만족하는 문자열을 태그를 제외한 나머지 부분만으로 치환시켜 버린다는 거죠. ^^;;
이걸로 대강 정규식에 대한 이해가 되었나요? 가능하면 쉽게 풀어쓰려고 했지만, 원래 어렵기도 하고 또 저도 시간에 쫓기다 보니 쉽지만은 않았네요. 더욱 더 고급응용을 하게 되면 템플릿을 만든다거나 하는 고급 활용도 가능하지만 이 부분은 접고 다른 걸 하도록 하죠.
원하시는 강의가 있으면 리플로 어택해주세요~ ^^
### 생각해볼 문제
야후 사이트 첫페이지에...
1. 사용된 a태그는 전부 몇 개일까요?
2. a 태그안에 사용된 URL만을 뽑아서 전부 출력해보세요.
3. 태그가 아닌 영문자 5글자 이상으로 이루어진 단어는 어떤 것들이 있는가?
댓글 9
-
yjae
2003.04.17 12:01
-
행복한고니
2003.04.17 16:30
yjae//생각해볼 강의를 추가했습니다. 왜 정규식을 사용하게 되는지...한번 활용해보세요.
저 같은 경우에는 preg_replace_callback 을 이용해서 게시판에 쓰일 간단한 템플릿 엔진을 만들었습니다. 스킨 디자인이 훨씬 쉽죠. ^^;; 또한 preg_match_all 을 이용해서 뉴스를 뽑아오도록 해둔 것도 있구요. 저는 이정도 밖에 사용하지 못하지만 활용하기에 따라서는 너무나도 다양한 기능을 간편하게 낼 수 있는 것이 바로 정규식입니다. -
이성완
2003.05.09 16:13
수고하십니다 고니님. 강좌 정말 잘보고 있는데요.
그런데 글중에
'preg_match의 경우라면 하나만 검사하게 되니까 $match[0] 과 $match[1] 은 배열이 아니게 됩니다. ' 이건 왜 배열이 아니죠?
preg_match를 이용시 match[0]은 패턴 전체값을. match[1]을 서버패턴값이 나오면서 1차배열이 형성이 되던데 말이죠. 단지 match_all은 서브패턴의 갯수에 따라 n차의 배열이 형성되고 그냥 preg_match는 1차배열안에 값이 다 들어간다는 의미인가요?
엉뚱한 질문이지만 전 이해가 안되어서요. ^^; -
이성완
2003.05.09 16:52
function callback_func($input){
if(!$input[1]){
return "http://".$input[0];
}
}
그리고 이부분 실제로 돌려보면 http://가있는 부분은 아예 아무값도 안들어가네요.
else return $input[0]; 라도 넣어주어야 하지 않나 싶은데요. 제가 정규식을 제대로 이해하는건지 모르겠네요...T_T -
이성완
2003.05.18 19:42
2번째 질문은
<?
$subject=<<<END
<html>
<body>
링크<br>
1. <a href="http://nzeo.com">NZEO.com </a>제로님의 NZEO.COM입니다. 너무 유명하죠?<br>
2. <A href="http://mygony.com">mygony.com</A> 제 홈입니다<br>
<br>
제 메일주소는요~~~~ gonom9@empal.com입니다.
</body>
</html>
END;
$pattern = "/(http://)?([a-zA-Z0-9_-]+.[a-zA-Z0-9_.-]+)/i";
echo preg_replace_callback($pattern, "callback_func", $subject);
function callback_func($input){
if(!$input[1]){
return "http://".$input[0];
}
}
?>
http://가그냥 있으면 나두어야 하는데 없애버려서요. 그와 관련된 리턴값은 없어서요. -
행복한고니
2003.05.13 02:08
이성완//
$match[0]과 $match[1] 자체가 배열이 아니란 말이었습니다. 그들은 단지 배열의 구성 요소일 뿐, 스스로 배열이 될 수 없죠. preg_match_all 같은 경우에는 $match[0] 이 배열의 형태로 존재해서 $match[0][0] 이나 $match[0][1] 과 같은 접근이 가능합니다. preg_match_all 이라도 n차의 배열이 형성되는 것이 아니라 배열의 깊이는 단지 2차원인데, $match[0]이라는 배열이 서브 패턴의 갯수에 따라 크기가 정해질 뿐입니다. 배열의 차수는 어느 정도의 깊이까지 접근하느냐로 구분하는 것입니다.
그리고 두번째 질문에 관해서는 정규식 패턴과 함수의 사용법을 알려주시는 것이 조금 더 확실한 답변을 드릴 수 있을 것 같습니다. -
이성완
2003.05.18 19:40
1번째 질문은.. 1차배열에서 어떻게 2차배열까지 접근이 가능한지 이해가 안되네요.
함수내에서 자체적으로 이미 1,2차 배열을 주는건 아닐까 싶어서요.
그리고 서브패턴이 있으면 엄격히 이야기해서 3차배열까지 가더군요.. -
행복한고니
2003.05.21 23:19
이성완님//
우선 preg_replace 가 동작하는 과정부터 생각해보면...
1. 일치하는 패턴을 찾는다.
2. callback 함수를 불러들인다.
3. 1에서 찾은 일치한 패턴을 callback 함수에서 return 한 값으로 바꾼다.
이제 눈치채셨을 겁니다.
이성완님의 callback_func 에는 http:// 가있을 때의 반환값이 없습니다. 즉,
function callback_func($input){
if(!$input[1]){
return "http://".$input[0];
}else return $input[0];
}
으로 바꾸어줘야 한다는 말이죠. ^^ -
김용식
2003.07.05 18:48
강의 잘 보았습니다.
대략 '짱' 이군요~
| 제목 | 글쓴이 | 날짜 |
|---|---|---|
| 군대간 친구 남은날짜 계산하기 [6] | xacdo | 2003.04.27 |
| 유용한 일반 함수 모음;ㅁ; [11] | TheMics | 2003.04.23 |
| 노프레임+프레임없이 접근막기+게시물 링크하기 [3] | teslaMINT | 2003.04.20 |
|
PHP 혼자 공부하기 - 12 :: SQL문
[6]
| 행복한고니 | 2003.04.20 |
| 데이터베이스, PHP를 만나면「알짜 사이트로 부활!」 [1] | .maya | 2003.04.18 |
|
[mics'php] 2. PHP 사용 시스템 구축하기
[3]
| TheMics | 2003.04.17 |
| [mics'php] 1. PHP란? [8] | TheMics | 2003.04.16 |
|
PHP 혼자 공부하기 - 11 :: 정규식 실전예제
[9]
| 행복한고니 | 2003.04.16 |
| PHP 혼자 공부하기 - 10 :: 정규식 패턴 문법 [3] | 행복한고니 | 2003.04.15 |
| PHP 혼자 공부하기 - 9 :: 정규식 함수 [3] | 행복한고니 | 2003.04.14 |
| PHP 혼자 공부하기 - 8 :: 시간다루기 [18] | 행복한고니 | 2003.04.13 |
| PHP 혼자 공부하기 - 7 :: 제어문과 함수 [7] | 행복한고니 | 2003.04.12 |
| [mics'php] 들어가기 전에 [1] | TheMics | 2003.04.11 |
| PHP 혼자 공부하기 - 6 :: 연산자 [7] | 행복한고니 | 2003.04.11 |
| PHP 혼자 공부하기 - 5 :: 변수 [4] | 행복한고니 | 2003.04.10 |
| PHP 혼자 공부하기 - 4 :: 미리 정의된 변수 [13] | 행복한고니 | 2003.04.09 |
| PHP 혼자 공부하기 - 3 :: 변수형 [8] | 행복한고니 | 2003.04.09 |
| PHP 혼자 공부하기 - 2 :: PHP의 시작 [9] | 행복한고니 | 2003.04.09 |
| PHP 혼자 공부하기 - 1 :: 준비물 [3] | 행복한고니 | 2003.04.09 |
| 개판 오분전 세션 - 7 [10] | 미친개 | 2003.04.08 |
다음 강의... 에... 괜찮으시다면~
세션의 활용~ 이나 가벼운 분위기로 고니님의 PHP 프로그래밍 스타일 (예를 들어서 PHP 만들때의 습관이라던지) 얘기해주시면 어떨까요? :) 아주 간단한거라도 미처 다른 사람이 생각 못 한 것들도 있을테니... ^^;;;
정말 <form action="test.php?id=test" method="post"> 같은건 생각 못했던 거랍니다;;;