웹마스터 팁
PHP 혼자 공부하기 - 12 :: SQL문
2003.04.20 19:18
오랜만에 또 쓰네요. 허접강의에도 관심가져주시는 분들이 꽤 있다는 것을 알고나니 가만히 있을 수가 없네요. ^^;;
MySQL, MSSQL, postgreSQL 등등 어디선가 한번은 들어보았을만한 DBMS들은(DBMS의 개념은 바로 아래에 있어요) 대게 ANSI SQL 라는 규약을 따르고 있는데, 이 때 공통적으로 쓰이는 것이 바로 SQL입니다. SQL이란 Structured Query Language(구조적 쿼리 언어)의 약자로 일종의 언어라는 형태로 존재함을 이름으로 알 수 있습니다. 이런 SQL을 쓰는 이유는 바로 DBMS들에게 명령을 내려서 원하는 결과를 얻고자 함입니다. 물론, 많은 DBMS들이 표준이외에도 이를 벗어난 SQL을 지원하고는 있지만 역시 기본은 표준아니겠습니까!! 표준을 먼저 익히고 나중에 DBMS별로 이를 벗어난 사용법을 익혀두는 것이 헛갈리지도 않고 기초가 튼튼한 바람직한(?) 인간이 되는 방법입니다. ^^
용어 DBMS(Database Management System)
여러가지 종류의 자료들을 보다 효율적으로 관리하기 위한 System입니다. 자료가 어느 정도 양이 되면 일정한 기준으로 이 자료들을 보다 효율적으로 관리 할 수 있어야 하는데 이를 위해서 Database(그냥 "자료의 집합"정도로 이해하시면 됩니다)를 구축하고 관리해줄 시스템이 필요하게 됩니다. 이게 바로 DBMS인 것이죠. DBMS의 종류는 상용으로 쓰이는 Oracle, MSSQL, Sybase, BerkeleyDB, Cache부터 오픈 소스의 MySQL, postgreSQL, mSQL, Firebird 등 매우 다양하고, 지금도 새로운 DBMS들이 만들어지고 있습니다. 보통 줄여서 DB나 데이타베이스(database)로 부르곤 하지만 정확한 명칭이 DBMS라는 것은 알고 사용하셔야 합니다. 또한 특별히 관계형 데이타베이스를 구축하고 사용하는 DBMS를 RDBMS(Relational ~~~)라고 부르기도 합니다. 예로 든 것들은 전부 RDBMS네요. ^^;;
RDMBS에 대해서 궁금하시면... http://terms.co.kr/RDBMS.htm 를 참고하세요.
SQL에 대해 들어가기 전에 잡설 좀 할께요. 제 강좌에서 일부러 영어 원문을 파헤쳐가면서 하는 이유는... 보시는 분들의 머리를 아프게 하기 위해서...(~~퍽!!)는 아니고, 이런걸 알아두면 유식하게 보일 수 있기 때문이죠!! 머리아프다고 생각하지 마시고 제 말 듣고 머리에 집어넣어 둬 보세요. 나중에 대화중 SQL이라는 이름이 나왔을 때 "아~ 스트럭쳐드 쿼리 랭귀지(혹은 구조적 쿼리 언어)?" 라고 하면... 유식하게 보일 수도 있습니다. 때에 따라선 "재섭서.."의 어택을 받을지도 모르지만... 쿨럭~
그래도 제가 강의하면서 약어의 원문을 파헤치니까 확실히 많이 아는 것 같지 않아요? 아님 말구요... ㅡ_ㅡ;;
잡설이 길었네요. 이제 SQL문에 대해 본격적으로 들어갑니다.
기본개념
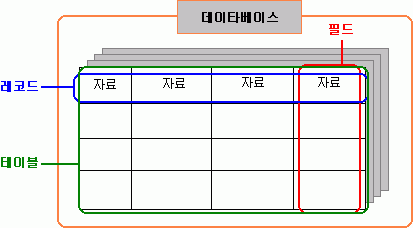
DB - DBMS에서의 DB란 "테이블의 집합"쯤으로 생각하시면 될 것 같습니다. 그리고 DBMS의 "관리단위"정도로 이해하셔도 되구요. 호스팅할 때는 사용자별로 DB를 나누는 것이 일반적입니다.
테이블(table) - 행과 열의 집합입니다. 각각의 열들은 같은 유형의 데이타들을 분류해놓는 것이며 필드(field)라고 부르고, 각각의 행들은 서로 연관이 있는 자료들을 포함하고 있으며 이들을 레코드(record)라고 부릅니다. 즉, 테이블이란 "레코드의 집합"으로 볼 수 있습니다.
레코드(record) - 서로 연관이 있는 자료들의 집합입니다.
필드(filed) - 같은 레코드의 데이타들은 그들의 자료형(정수, 문자)과 크기, 사용처 등 다양한 기준으로 따라서 나눌 수 있는데 이 때 이런 구분의 단위를 필드라고 합니다. 각각의 필드는 독립적인 자료로 인식합니다.
이제 예를 들어서 설명을 합니다. 학생들의 성적표를 하나의 DB에 넣는다고 가정합니다.
학생들의 신상자료에 이름, 성별, 국어점수, 영어점수, 수학점수 가 있다고 했을 때 각각의 이름, 성별... 등을 필드라고 합니다. 국어점수와 영어점수는 엄연히 서로 다른 자료이므로 서로 구분을 하게 되는 것이죠. 이것이 필드의 개념입니다. 그리고 각각의 자료들을 "학생별"로 관리하게 되는데 이 때 "학생별"이라는 것의 기준이 바로 레코드입니다. 레코드를 모아놓은 것이 바로 테이블이죠. ^^
행을 추가하거나 삭제하기는 쉽지만, 필드를 수정하거나 삭제하는 것은 때에 따라선 시스템의 성능을 상당히 저하시키는 일이 될 수도 있다는 것을 명심하시고 종이와 연필을 가지고 그려보기 시작해보세요. 학생들의 자료를 관리할 때 과연 어떻게 하게 될 것인지를요. 역시 행별로는 학생의 이름을 넣는 것이 편하겠죠? 자료를 각각의 연관성이 있는 단위로 묶어놓은 것이 레코드라는 말... 이해가 가시는지요? 아직도 개념이 안 서셨다면 다시한번 주욱 읽으세요. 그리고 이해여부와 관계없이 다음 글을 읽으시면 됩니다.
SQL문
SQL문 중에서도 기본적인 사용법만 익혀보도록 하겠습니다. 또한 강의내용은 ANSI SQL 즉 표준 SQL이며, 따라서 대부분의 DBMS에서 적용가능합니다. 표준의 지반위에 쌓은 공든탑은 무너지지 않습니다. +_+
1. INSERT
DB에 자료를 넣을 때 씁니다. 사용법은 다음과 같습니다.
INSERT INTO 테이블명 VALUES (value1, value2, ...) 혹은
INSERT INTO 테이블명 (field1, field2, ...) VALUES (values1, values2, ...)
첫번째 방법은 모든 필드에 자료를 넣을 때 사용합니다. 즉, 앞에서 부터 첫번째 필드, 두번째 필드 이런식으로 값이 저장됩니다. 두번째 방법은 특정 필드에만 자료를 넣을 때 사용합니다. 꼭 만들어진 순서대로 저장할 필요도 없습니다. 예를 들어, 다음과 같은 테이블이 있습니다(테이블명 : student).
┌───┬───┬───┬────┐
│이 름│학 번│학 과│자기소개│
├───┼───┼───┼────┤
│김누구│200242│컴퓨터│헤헤 │
~~~~~~~~~~~~~~~~~~~~~~~~~~
저기에 새로운 자료를 넣는다고 하면...
INSERT INTO student VALUES ('김누구', 200242, '컴퓨터', '헤헤');
와 같이 쓸 수도 있지만...
INSERT INTO student (name, hakbun, hakgwa, sogae) VALUES ('김누구', 200242, '컴퓨터', '헤헤');
와 같이 쓸 수도 있으며,
INSERT INTO student (name, hakgwa, hakbun, sogae) VALUES ('김누구', '컴퓨터', 200242, '헤헤');
와 같이 쓸 수도 있고,
INSERT INTO student (name, hakgwa, hakbun) VALUES ('김누구', '컴퓨터', 200242);
와 같이 쓸 수도 있습니다. 물론 마지막 경우에는 자기소개의 내용이 입력되지 않겠죠. ^^ 또한 문자열은 작은 따옴표를 붙여줘야 합니다. *^^*
2. UPDATE
이미 저장되어있는 자료를 수정할 때 사용합니다. 사용은 다음과 같이 합니다.
UPDATE 테이블 SET 필드1=값1, 필드2=값2 [WHERE 조건]
만약 WHERE 절을 붙이지 않는다면 해당 테이블에 있는 모든 레코드에 대해서 필드값을 조정합니다. 의도한 것이라면 관계없지만 실수로 WHERE 절을 붙이지 않았다면... 때에 따라서는 등 뒤에 흐르는 전기를 맛볼 수도 있습니다(경험자라는...ㅠ_ㅠ). INSERT 문에 쓰였던 데이타 있죠? 여기에서 사람이름을 수정한다고 하면...
UPDATE student SET name='김무엇'
이렇게 쓰면... 될까요? 당연히 안되죠. 그랬다가는 student 테이블에 있는 모든 학생의 이름이 "김무엇"으로 바뀌어 버릴테니까요. 따라서, WHERE 조건절을 지정해줘야 합니다. 학번이 200242 인 사람의 이름을 "김무엇"으로 바꾸어 보도록 하겠습니다.
UPDATE student SET name='김무엇' WHERE hakbun=200242
자... 그럼 이렇게...
┌───┬───┬───┬────┐
│이 름│학 번│학 과│자기소개│
├───┼───┼───┼────┤
│김무엇│200242│컴퓨터│헤헤 │
~~~~~~~~~~~~~~~~~~~~~~~~~~
결과가 나오게 됩니다. 만약 WHERE 조건에 해당하는 레코드가 없다면 당연히 DBMS는 아무것도 업데이트 시키지 않고 명령을 종료하게 됩니다.
3. SELECT
저장되어있는 자료를 가지고 올 때 씁니다. 저것만 덩그러니 서놓아봤자 어디에서 무엇을 가져와야하는지 알지 못하는 컴퓨터는 바~~~보이므로... 사람이 알려줘야합니다. *^^*
SELECT 필드리스트 FROM 테이블명 [WHERE 조건문]
역시 WHERE 절은 생략가능합니다. 그러면 쿼리한 결과는 해당테이블에서 정해진 필드의 데이타를 모두 가지고 옵니다.
자... 위에서 학번과 학과만 골라온다고 하면...
SELECT hakbun, hakgwa FROM student
와 같이 쓸 수 있습니다. 그러면 결과는...
┌───┬───┐
│학 번│학 과│
├───┼───┤
│200242│컴퓨터│
~~~~~~~~~~~~~
와 같이 학번과 학과만 뽑아져 옵니다. 다른 데이타는 찾아봐도 없어요.. ㅡ_ㅡ;;
만약 모든 필드를 지정해주고 싶다면, 필드명을 하나하나 쓰는 방법도 있지만, 와일드카드(*)를 쓰는 방법도 있습니다.
SELECT * FROM student
간단하죠? 만약 학번이 200245인 사람의 자료를 가지고 오고 싶다고 하는 식으로 특수한 조건을 만족하는 자료만 뽑아오고 싶을 때가 있는데 이럴 때는...
SELECT * FROM student WHERE hakbun=200245
와 같이 쓸 수 있습니다.
4. DELETE
DELETE 는 정말 쉽습니다.
DELETE FROM 테이블명[ WHERE 조건절]
척 봐도 이해가 되죠? 조건에 맞는 자료를 삭제해주는 겁니다. 만약 조건절이 없다면...? 무시무시한 결과를 맞이하게 됩니다. 그 테이블에 있는 자료가 싸~~~악 날아가죠. 만약 개인 자료였다면 짜증만 나고 말겠지만... 회사나 단체의 데이터라면... 등에 식은 땀이 주욱 흐르는 공포를 맛볼 수 있습니다.(예전에 회사에서 일할 때 회원정보를 날려먹은 적이 있다는... ㅠ_ㅠ)
DELETE FROM student WHERE hakbun=200245
와 같이 사용하시면 됩니다.
5. 조건절 고급
여태까지는 조건절을 WHERE 필드명=조건과 같은 식으로 단순하게만 썼습니다만...
이번에는 조금 다른 식으로 써보겠습니다. 이름이 김씨인 사람의 자료를 뽑아오려는데, 과연 김~~ 라는 이름은 어떻게 조건을 줄 것인가? 그건 바로 이렇게 합니다.
SELECT * FROM student WHERE name LIKE '김%'
SQL문에서 %는 어떤 문자라도 올 수 있음을 의미합니다. 심지어는 "김"이라는 자료만 가졌어도 결과를 뽑아오게 됩니다. 만약 이름에 "태"라는 단어가 들어가는 사람을 찾으려면...
SELECT * FROM student WHERE name LIKE '%태%'
와 같이 앞에 써주시면 됩니다. 참고로 LIKE문은 대소문자 구별을 하지 않습니다.
그럼 성이 김씨이면서(성이 김씨라는 말을 DB상의 의미로는 '이름'이라는 문자열의 제일 첫글자가 '김' 이라는 말로 생각해야합니다) 학과가 컴퓨터인 사람을 찾으려면 어떻게 해야할까요? 우선 조건을 생각해봅니다.
1. 'name' 필드 문자열의 제일 첫 문자가 '김' 이다.
2. 학과의 이름은 '컴퓨터'이다.
3. 1,2 번 조건을 '모두' 만족해야 한다.
SELECT * FROM student WHERE name LIKE '김%' AND hakgwa = '컴퓨터'
이해가 되시는 지요? 두 조건을 모두 만족하려면 AND 기호로 각각의 조건들을 이어줍니다. 다음과 같은 식의 사용도 가능합니다.
SELECT * FROM student WHERE name LIKE '김%' AND hakgwa = '컴퓨터' AND hakjum < 4 AND hakjum > 3
즉, 차례대로 조건을 따져가면...
1. '김' 씨이면서,
2. '컴퓨터' 학과인 사람들 중
3. '학점'이 4보다 작고
4. '학점'이 3보다 큰
학생은...?
이라는 것으로 해석할 수 있습니다. 즉, 모두가 AND 로 이어졌으므로 1,2,3,4의 모든 조건을 만족하는 자료를 가지고 오게 됩니다.
그럼 학과가 '컴퓨터' 학과이거나(조건을 잘 보세욧!) 학점이 3 이상인 사람들을 찾으려면?
그럴 때 쓰는 구문이 OR 구문입니다. 즉, OR로 연결된 조건들 중 하나만 만족시켜도 되는 것이죠.
SELECT * FROM student WHERE hakgwa = '컴퓨터' OR hakjum > 3
OR 역시 AND 처럼 여러개를 이어써도 됩니다. ^^
그럼 조금 더 [고급]으로~ 넘어갑니다. 성이 '김'이면서 학점이 3 이상인 사람들이나 성이 '박' 이면서 학점이 3 이상인 사람들을 찾을 때는 어떻게 해야할까요? 우선 조건을 생각해봅시다.
1. 성이 '김' 이어야 한다.
2. 성이 '박' 이어야 한다.
3. 학점은 3 이상이어야 한다.
4. 1, 2의 조건 중 하나만 만족시켜도 되며, 3의 조건은 반드시 만족시켜야 한다.
그럼 이제 쿼리문을 작성해봅시다.
SELECT * FROM student WHERE (name LIKE '김%' OR name LIKE '박%') AND hakjum > 3
모든 프로그래밍 언어에서(적어도 제가 아는) 괄호의 처리는 괄호 바깥의 처리에 대해서 보호받습니다. 수학에서 (3+4) * 8 과 같이 사용하듯, 보호해서 먼저 처리해야할 부분에 대해서는 괄호 처리를 해줍니다. 위 구문은 괄호의 위치를 바꾸어서
SELECT * FROM student WHERE hakjum > 3 AND (name LIKE '김%' OR name LIKE '박%')
와 같이 사용하셔도 됩니다.
6. 결과값 정렬
이번에는 결과값을 정렬하는 법을 알아보도록 하겠습니다. 우선 결과값은 다음과 같이 사용합니다.
~~~~ ORDER BY 기준필드 [ASC OR DESC]
간단하죠? 예를 들어 위에서 뽑아온 자료를 사람들의 학점별로 정렬을 하려면...
SELECT * FROM student WHERE hakjum > 3 ORDER BY hakjum
만약 ASC나 DESC 등을 쓰지 않으면 자동적으로 ASC로 인식이 됩니다. 즉 위의 것은
SELECT * FROM student WHERE hakjum > 3 ORDER BY hakjum ASC
와 같은 말입니다. 그럼 ASC와 DESC의 차이는 뭘까요? 지금부터 그것에 대해서 설명하겠습니다.
┌───┬───┐
│학 번│학 점│
├───┼───┤
│200242│ 3.5 │
├───┼───┤
│200243│ 3.8 │
├───┼───┤
│200245│ 3.2 │
├───┼───┤
│200254│ 3.4 │
~~~~~~~~~~~~~
위와 같은 자료가 있다고 합시다. 보통은 자료를 입력했던 순서대로 필드가 정렬됩니다. 하지만, 학번에 따라서 성적이 좌우되는 것은 아니기 때문에 만약 성적순으로 자료를 보고 싶다면 어떻게 해야할까요? 당연히 정렬을 써야겠죠. ^^;; 그럼 성적이 높은 사람부터 낮은 사람순으로 자료를 뽑아오고 싶다면요?
~~~ ORDER BY hakjum DESC
DESC 란 descend 즉, 감소의 의미를 가지고 있습니다. 값이 높은 것부터 낮은 것 순으로 정렬하죠.
그럼 ASC의 의미도 알 수 있겠죠? ascend 즉, 증가의 의미를 가지고 있으며 값이 낮은 것부터 높은 것 순으로 정렬합니다. 이것은 꼭 숫자의 형태를 가진 자료뿐 아니라 문자열에도 쓰입니다. 우리가 흔히 ASCII 코드라고 부르는 것을 기준으로 정렬되죠. ^^ 한글의 정렬도 대부분은 잘 되는 편입니다. 확장완성형이라는 변종 규칙에 의해서 줄 잘못선(?) 문자가 몇개 있기는 하지만 그래도 대부분은 잘 됩니다. -_-;;
학점순으로 정렬해놓고 보기편하게 "같은 점수라면 학번순으로 정렬" 이라는 조건을 주려면?
~~~ ORDER BY hakjum DESC, hakbun
보시다시피 컴마로 구분합니다. 학번뒤쪽에 ASC가 생략되어있음을 다시 말하지 않아도 되겠죠? 흔히 성적은 높은 사람이 위로 오게, 그리고 학번은 빠른 번호(즉, 숫자가 작은)가 위에 오도록 정렬하는 것이 일반적이므로 DESC와 ASC를 적절하게 사용했습니다. 만약
~~~ ORDER BY hakbun, hakjum DESC
과 같이 사용하게 되면 의미는 완전히 달라지게 됩니다.
"hakbun이 빠른 사람이 위에 오도록 하되, 같은 학번이라면 학점 높은 사람이 위로 오게" 라는 의미가 되는 거죠. 실제로는 학번이 같은 사람은 없으므로 위의 결과는
~~~ ORDER BY hakbun
과 같이 나오게 됩니다. ^^
MySQL, MSSQL, postgreSQL 등등 어디선가 한번은 들어보았을만한 DBMS들은(DBMS의 개념은 바로 아래에 있어요) 대게 ANSI SQL 라는 규약을 따르고 있는데, 이 때 공통적으로 쓰이는 것이 바로 SQL입니다. SQL이란 Structured Query Language(구조적 쿼리 언어)의 약자로 일종의 언어라는 형태로 존재함을 이름으로 알 수 있습니다. 이런 SQL을 쓰는 이유는 바로 DBMS들에게 명령을 내려서 원하는 결과를 얻고자 함입니다. 물론, 많은 DBMS들이 표준이외에도 이를 벗어난 SQL을 지원하고는 있지만 역시 기본은 표준아니겠습니까!! 표준을 먼저 익히고 나중에 DBMS별로 이를 벗어난 사용법을 익혀두는 것이 헛갈리지도 않고 기초가 튼튼한 바람직한(?) 인간이 되는 방법입니다. ^^
용어 DBMS(Database Management System)
여러가지 종류의 자료들을 보다 효율적으로 관리하기 위한 System입니다. 자료가 어느 정도 양이 되면 일정한 기준으로 이 자료들을 보다 효율적으로 관리 할 수 있어야 하는데 이를 위해서 Database(그냥 "자료의 집합"정도로 이해하시면 됩니다)를 구축하고 관리해줄 시스템이 필요하게 됩니다. 이게 바로 DBMS인 것이죠. DBMS의 종류는 상용으로 쓰이는 Oracle, MSSQL, Sybase, BerkeleyDB, Cache부터 오픈 소스의 MySQL, postgreSQL, mSQL, Firebird 등 매우 다양하고, 지금도 새로운 DBMS들이 만들어지고 있습니다. 보통 줄여서 DB나 데이타베이스(database)로 부르곤 하지만 정확한 명칭이 DBMS라는 것은 알고 사용하셔야 합니다. 또한 특별히 관계형 데이타베이스를 구축하고 사용하는 DBMS를 RDBMS(Relational ~~~)라고 부르기도 합니다. 예로 든 것들은 전부 RDBMS네요. ^^;;
RDMBS에 대해서 궁금하시면... http://terms.co.kr/RDBMS.htm 를 참고하세요.
SQL에 대해 들어가기 전에 잡설 좀 할께요. 제 강좌에서 일부러 영어 원문을 파헤쳐가면서 하는 이유는... 보시는 분들의 머리를 아프게 하기 위해서...(~~퍽!!)는 아니고, 이런걸 알아두면 유식하게 보일 수 있기 때문이죠!! 머리아프다고 생각하지 마시고 제 말 듣고 머리에 집어넣어 둬 보세요. 나중에 대화중 SQL이라는 이름이 나왔을 때 "아~ 스트럭쳐드 쿼리 랭귀지(혹은 구조적 쿼리 언어)?" 라고 하면... 유식하게 보일 수도 있습니다. 때에 따라선 "재섭서.."의 어택을 받을지도 모르지만... 쿨럭~
그래도 제가 강의하면서 약어의 원문을 파헤치니까 확실히 많이 아는 것 같지 않아요? 아님 말구요... ㅡ_ㅡ;;
잡설이 길었네요. 이제 SQL문에 대해 본격적으로 들어갑니다.
기본개념
DB - DBMS에서의 DB란 "테이블의 집합"쯤으로 생각하시면 될 것 같습니다. 그리고 DBMS의 "관리단위"정도로 이해하셔도 되구요. 호스팅할 때는 사용자별로 DB를 나누는 것이 일반적입니다.
테이블(table) - 행과 열의 집합입니다. 각각의 열들은 같은 유형의 데이타들을 분류해놓는 것이며 필드(field)라고 부르고, 각각의 행들은 서로 연관이 있는 자료들을 포함하고 있으며 이들을 레코드(record)라고 부릅니다. 즉, 테이블이란 "레코드의 집합"으로 볼 수 있습니다.
레코드(record) - 서로 연관이 있는 자료들의 집합입니다.
필드(filed) - 같은 레코드의 데이타들은 그들의 자료형(정수, 문자)과 크기, 사용처 등 다양한 기준으로 따라서 나눌 수 있는데 이 때 이런 구분의 단위를 필드라고 합니다. 각각의 필드는 독립적인 자료로 인식합니다.
이제 예를 들어서 설명을 합니다. 학생들의 성적표를 하나의 DB에 넣는다고 가정합니다.
학생들의 신상자료에 이름, 성별, 국어점수, 영어점수, 수학점수 가 있다고 했을 때 각각의 이름, 성별... 등을 필드라고 합니다. 국어점수와 영어점수는 엄연히 서로 다른 자료이므로 서로 구분을 하게 되는 것이죠. 이것이 필드의 개념입니다. 그리고 각각의 자료들을 "학생별"로 관리하게 되는데 이 때 "학생별"이라는 것의 기준이 바로 레코드입니다. 레코드를 모아놓은 것이 바로 테이블이죠. ^^
행을 추가하거나 삭제하기는 쉽지만, 필드를 수정하거나 삭제하는 것은 때에 따라선 시스템의 성능을 상당히 저하시키는 일이 될 수도 있다는 것을 명심하시고 종이와 연필을 가지고 그려보기 시작해보세요. 학생들의 자료를 관리할 때 과연 어떻게 하게 될 것인지를요. 역시 행별로는 학생의 이름을 넣는 것이 편하겠죠? 자료를 각각의 연관성이 있는 단위로 묶어놓은 것이 레코드라는 말... 이해가 가시는지요? 아직도 개념이 안 서셨다면 다시한번 주욱 읽으세요. 그리고 이해여부와 관계없이 다음 글을 읽으시면 됩니다.
SQL문
SQL문 중에서도 기본적인 사용법만 익혀보도록 하겠습니다. 또한 강의내용은 ANSI SQL 즉 표준 SQL이며, 따라서 대부분의 DBMS에서 적용가능합니다. 표준의 지반위에 쌓은 공든탑은 무너지지 않습니다. +_+
1. INSERT
DB에 자료를 넣을 때 씁니다. 사용법은 다음과 같습니다.
INSERT INTO 테이블명 VALUES (value1, value2, ...) 혹은
INSERT INTO 테이블명 (field1, field2, ...) VALUES (values1, values2, ...)
첫번째 방법은 모든 필드에 자료를 넣을 때 사용합니다. 즉, 앞에서 부터 첫번째 필드, 두번째 필드 이런식으로 값이 저장됩니다. 두번째 방법은 특정 필드에만 자료를 넣을 때 사용합니다. 꼭 만들어진 순서대로 저장할 필요도 없습니다. 예를 들어, 다음과 같은 테이블이 있습니다(테이블명 : student).
┌───┬───┬───┬────┐
│이 름│학 번│학 과│자기소개│
├───┼───┼───┼────┤
│김누구│200242│컴퓨터│헤헤 │
~~~~~~~~~~~~~~~~~~~~~~~~~~
저기에 새로운 자료를 넣는다고 하면...
INSERT INTO student VALUES ('김누구', 200242, '컴퓨터', '헤헤');
와 같이 쓸 수도 있지만...
INSERT INTO student (name, hakbun, hakgwa, sogae) VALUES ('김누구', 200242, '컴퓨터', '헤헤');
와 같이 쓸 수도 있으며,
INSERT INTO student (name, hakgwa, hakbun, sogae) VALUES ('김누구', '컴퓨터', 200242, '헤헤');
와 같이 쓸 수도 있고,
INSERT INTO student (name, hakgwa, hakbun) VALUES ('김누구', '컴퓨터', 200242);
와 같이 쓸 수도 있습니다. 물론 마지막 경우에는 자기소개의 내용이 입력되지 않겠죠. ^^ 또한 문자열은 작은 따옴표를 붙여줘야 합니다. *^^*
2. UPDATE
이미 저장되어있는 자료를 수정할 때 사용합니다. 사용은 다음과 같이 합니다.
UPDATE 테이블 SET 필드1=값1, 필드2=값2 [WHERE 조건]
만약 WHERE 절을 붙이지 않는다면 해당 테이블에 있는 모든 레코드에 대해서 필드값을 조정합니다. 의도한 것이라면 관계없지만 실수로 WHERE 절을 붙이지 않았다면... 때에 따라서는 등 뒤에 흐르는 전기를 맛볼 수도 있습니다(경험자라는...ㅠ_ㅠ). INSERT 문에 쓰였던 데이타 있죠? 여기에서 사람이름을 수정한다고 하면...
UPDATE student SET name='김무엇'
이렇게 쓰면... 될까요? 당연히 안되죠. 그랬다가는 student 테이블에 있는 모든 학생의 이름이 "김무엇"으로 바뀌어 버릴테니까요. 따라서, WHERE 조건절을 지정해줘야 합니다. 학번이 200242 인 사람의 이름을 "김무엇"으로 바꾸어 보도록 하겠습니다.
UPDATE student SET name='김무엇' WHERE hakbun=200242
자... 그럼 이렇게...
┌───┬───┬───┬────┐
│이 름│학 번│학 과│자기소개│
├───┼───┼───┼────┤
│김무엇│200242│컴퓨터│헤헤 │
~~~~~~~~~~~~~~~~~~~~~~~~~~
결과가 나오게 됩니다. 만약 WHERE 조건에 해당하는 레코드가 없다면 당연히 DBMS는 아무것도 업데이트 시키지 않고 명령을 종료하게 됩니다.
3. SELECT
저장되어있는 자료를 가지고 올 때 씁니다. 저것만 덩그러니 서놓아봤자 어디에서 무엇을 가져와야하는지 알지 못하는 컴퓨터는 바~~~보이므로... 사람이 알려줘야합니다. *^^*
SELECT 필드리스트 FROM 테이블명 [WHERE 조건문]
역시 WHERE 절은 생략가능합니다. 그러면 쿼리한 결과는 해당테이블에서 정해진 필드의 데이타를 모두 가지고 옵니다.
자... 위에서 학번과 학과만 골라온다고 하면...
SELECT hakbun, hakgwa FROM student
와 같이 쓸 수 있습니다. 그러면 결과는...
┌───┬───┐
│학 번│학 과│
├───┼───┤
│200242│컴퓨터│
~~~~~~~~~~~~~
와 같이 학번과 학과만 뽑아져 옵니다. 다른 데이타는 찾아봐도 없어요.. ㅡ_ㅡ;;
만약 모든 필드를 지정해주고 싶다면, 필드명을 하나하나 쓰는 방법도 있지만, 와일드카드(*)를 쓰는 방법도 있습니다.
SELECT * FROM student
간단하죠? 만약 학번이 200245인 사람의 자료를 가지고 오고 싶다고 하는 식으로 특수한 조건을 만족하는 자료만 뽑아오고 싶을 때가 있는데 이럴 때는...
SELECT * FROM student WHERE hakbun=200245
와 같이 쓸 수 있습니다.
4. DELETE
DELETE 는 정말 쉽습니다.
DELETE FROM 테이블명[ WHERE 조건절]
척 봐도 이해가 되죠? 조건에 맞는 자료를 삭제해주는 겁니다. 만약 조건절이 없다면...? 무시무시한 결과를 맞이하게 됩니다. 그 테이블에 있는 자료가 싸~~~악 날아가죠. 만약 개인 자료였다면 짜증만 나고 말겠지만... 회사나 단체의 데이터라면... 등에 식은 땀이 주욱 흐르는 공포를 맛볼 수 있습니다.(예전에 회사에서 일할 때 회원정보를 날려먹은 적이 있다는... ㅠ_ㅠ)
DELETE FROM student WHERE hakbun=200245
와 같이 사용하시면 됩니다.
5. 조건절 고급
여태까지는 조건절을 WHERE 필드명=조건과 같은 식으로 단순하게만 썼습니다만...
이번에는 조금 다른 식으로 써보겠습니다. 이름이 김씨인 사람의 자료를 뽑아오려는데, 과연 김~~ 라는 이름은 어떻게 조건을 줄 것인가? 그건 바로 이렇게 합니다.
SELECT * FROM student WHERE name LIKE '김%'
SQL문에서 %는 어떤 문자라도 올 수 있음을 의미합니다. 심지어는 "김"이라는 자료만 가졌어도 결과를 뽑아오게 됩니다. 만약 이름에 "태"라는 단어가 들어가는 사람을 찾으려면...
SELECT * FROM student WHERE name LIKE '%태%'
와 같이 앞에 써주시면 됩니다. 참고로 LIKE문은 대소문자 구별을 하지 않습니다.
그럼 성이 김씨이면서(성이 김씨라는 말을 DB상의 의미로는 '이름'이라는 문자열의 제일 첫글자가 '김' 이라는 말로 생각해야합니다) 학과가 컴퓨터인 사람을 찾으려면 어떻게 해야할까요? 우선 조건을 생각해봅니다.
1. 'name' 필드 문자열의 제일 첫 문자가 '김' 이다.
2. 학과의 이름은 '컴퓨터'이다.
3. 1,2 번 조건을 '모두' 만족해야 한다.
SELECT * FROM student WHERE name LIKE '김%' AND hakgwa = '컴퓨터'
이해가 되시는 지요? 두 조건을 모두 만족하려면 AND 기호로 각각의 조건들을 이어줍니다. 다음과 같은 식의 사용도 가능합니다.
SELECT * FROM student WHERE name LIKE '김%' AND hakgwa = '컴퓨터' AND hakjum < 4 AND hakjum > 3
즉, 차례대로 조건을 따져가면...
1. '김' 씨이면서,
2. '컴퓨터' 학과인 사람들 중
3. '학점'이 4보다 작고
4. '학점'이 3보다 큰
학생은...?
이라는 것으로 해석할 수 있습니다. 즉, 모두가 AND 로 이어졌으므로 1,2,3,4의 모든 조건을 만족하는 자료를 가지고 오게 됩니다.
그럼 학과가 '컴퓨터' 학과이거나(조건을 잘 보세욧!) 학점이 3 이상인 사람들을 찾으려면?
그럴 때 쓰는 구문이 OR 구문입니다. 즉, OR로 연결된 조건들 중 하나만 만족시켜도 되는 것이죠.
SELECT * FROM student WHERE hakgwa = '컴퓨터' OR hakjum > 3
OR 역시 AND 처럼 여러개를 이어써도 됩니다. ^^
그럼 조금 더 [고급]으로~ 넘어갑니다. 성이 '김'이면서 학점이 3 이상인 사람들이나 성이 '박' 이면서 학점이 3 이상인 사람들을 찾을 때는 어떻게 해야할까요? 우선 조건을 생각해봅시다.
1. 성이 '김' 이어야 한다.
2. 성이 '박' 이어야 한다.
3. 학점은 3 이상이어야 한다.
4. 1, 2의 조건 중 하나만 만족시켜도 되며, 3의 조건은 반드시 만족시켜야 한다.
그럼 이제 쿼리문을 작성해봅시다.
SELECT * FROM student WHERE (name LIKE '김%' OR name LIKE '박%') AND hakjum > 3
모든 프로그래밍 언어에서(적어도 제가 아는) 괄호의 처리는 괄호 바깥의 처리에 대해서 보호받습니다. 수학에서 (3+4) * 8 과 같이 사용하듯, 보호해서 먼저 처리해야할 부분에 대해서는 괄호 처리를 해줍니다. 위 구문은 괄호의 위치를 바꾸어서
SELECT * FROM student WHERE hakjum > 3 AND (name LIKE '김%' OR name LIKE '박%')
와 같이 사용하셔도 됩니다.
6. 결과값 정렬
이번에는 결과값을 정렬하는 법을 알아보도록 하겠습니다. 우선 결과값은 다음과 같이 사용합니다.
~~~~ ORDER BY 기준필드 [ASC OR DESC]
간단하죠? 예를 들어 위에서 뽑아온 자료를 사람들의 학점별로 정렬을 하려면...
SELECT * FROM student WHERE hakjum > 3 ORDER BY hakjum
만약 ASC나 DESC 등을 쓰지 않으면 자동적으로 ASC로 인식이 됩니다. 즉 위의 것은
SELECT * FROM student WHERE hakjum > 3 ORDER BY hakjum ASC
와 같은 말입니다. 그럼 ASC와 DESC의 차이는 뭘까요? 지금부터 그것에 대해서 설명하겠습니다.
┌───┬───┐
│학 번│학 점│
├───┼───┤
│200242│ 3.5 │
├───┼───┤
│200243│ 3.8 │
├───┼───┤
│200245│ 3.2 │
├───┼───┤
│200254│ 3.4 │
~~~~~~~~~~~~~
위와 같은 자료가 있다고 합시다. 보통은 자료를 입력했던 순서대로 필드가 정렬됩니다. 하지만, 학번에 따라서 성적이 좌우되는 것은 아니기 때문에 만약 성적순으로 자료를 보고 싶다면 어떻게 해야할까요? 당연히 정렬을 써야겠죠. ^^;; 그럼 성적이 높은 사람부터 낮은 사람순으로 자료를 뽑아오고 싶다면요?
~~~ ORDER BY hakjum DESC
DESC 란 descend 즉, 감소의 의미를 가지고 있습니다. 값이 높은 것부터 낮은 것 순으로 정렬하죠.
그럼 ASC의 의미도 알 수 있겠죠? ascend 즉, 증가의 의미를 가지고 있으며 값이 낮은 것부터 높은 것 순으로 정렬합니다. 이것은 꼭 숫자의 형태를 가진 자료뿐 아니라 문자열에도 쓰입니다. 우리가 흔히 ASCII 코드라고 부르는 것을 기준으로 정렬되죠. ^^ 한글의 정렬도 대부분은 잘 되는 편입니다. 확장완성형이라는 변종 규칙에 의해서 줄 잘못선(?) 문자가 몇개 있기는 하지만 그래도 대부분은 잘 됩니다. -_-;;
학점순으로 정렬해놓고 보기편하게 "같은 점수라면 학번순으로 정렬" 이라는 조건을 주려면?
~~~ ORDER BY hakjum DESC, hakbun
보시다시피 컴마로 구분합니다. 학번뒤쪽에 ASC가 생략되어있음을 다시 말하지 않아도 되겠죠? 흔히 성적은 높은 사람이 위로 오게, 그리고 학번은 빠른 번호(즉, 숫자가 작은)가 위에 오도록 정렬하는 것이 일반적이므로 DESC와 ASC를 적절하게 사용했습니다. 만약
~~~ ORDER BY hakbun, hakjum DESC
과 같이 사용하게 되면 의미는 완전히 달라지게 됩니다.
"hakbun이 빠른 사람이 위에 오도록 하되, 같은 학번이라면 학점 높은 사람이 위로 오게" 라는 의미가 되는 거죠. 실제로는 학번이 같은 사람은 없으므로 위의 결과는
~~~ ORDER BY hakbun
과 같이 나오게 됩니다. ^^
댓글 6
-
방랑돌이
2003.04.29 02:44
-
행복한고니
2003.04.30 16:25
감사합니다. 제 강의가 도움이 되었다니 고맙습니다. ^^ -
세타
2003.05.11 03:53
으음. 아직도 미완성인건가요? 행복한고니님께서 쓰시는 글들,
정말 PHP 혼자 공부할 수 있을 정도로 하나하나씩 짚어주시네요.
정말 잘 읽고 있고요. 정말 감사합니다 :) -
행복한고니
2003.05.13 02:35
회사일이 바뻐서 꾸준히 못 쓰고 있네요. 윈도우즈 도움말 형태로 만들어 둔 것도 있는데... 에혀... 시간날 때마다 아주 조금씩 눈치봐가면서{ (-- ) ( --) 샤샤샥~ } 쓰고 있습니다. ^^;; -
CityBoys-Life
2003.07.01 22:43
여기서
$today = date("Y/m/d")
$end = $end_date < $today
UPDATE $member_table SET level=9 WHERE $end
위소스로 작동이 되는지 알고 싶습니다...
관리자를 제외한 레벨8회원만 골라 위소스를 작동시켜야 하는데 방법이 맞는지 봐주세요.. -
BelldandY
2003.07.14 16:44
CityBoys-Life // 안될꺼 같은데여..
레벨 8 인사람 중 관리자가 아닌 사람을 고를려면
where 조건에서, 레벨=8 AND 레벨<>관리자
이렇게 주면 될꺼 같네요..
레벨 이라는 글자 대신에는, 컬럼명이 들어가야겠죠.. ^^
| 제목 | 글쓴이 | 날짜 |
|---|---|---|
| 군대간 친구 남은날짜 계산하기 [6] | xacdo | 2003.04.27 |
| 유용한 일반 함수 모음;ㅁ; [11] | TheMics | 2003.04.23 |
| 노프레임+프레임없이 접근막기+게시물 링크하기 [3] | teslaMINT | 2003.04.20 |
|
PHP 혼자 공부하기 - 12 :: SQL문
[6]
| 행복한고니 | 2003.04.20 |
| 데이터베이스, PHP를 만나면「알짜 사이트로 부활!」 [1] | .maya | 2003.04.18 |
|
[mics'php] 2. PHP 사용 시스템 구축하기
[3]
| TheMics | 2003.04.17 |
| [mics'php] 1. PHP란? [8] | TheMics | 2003.04.16 |
|
PHP 혼자 공부하기 - 11 :: 정규식 실전예제
[9]
| 행복한고니 | 2003.04.16 |
| PHP 혼자 공부하기 - 10 :: 정규식 패턴 문법 [3] | 행복한고니 | 2003.04.15 |
| PHP 혼자 공부하기 - 9 :: 정규식 함수 [3] | 행복한고니 | 2003.04.14 |
| PHP 혼자 공부하기 - 8 :: 시간다루기 [18] | 행복한고니 | 2003.04.13 |
| PHP 혼자 공부하기 - 7 :: 제어문과 함수 [7] | 행복한고니 | 2003.04.12 |
| [mics'php] 들어가기 전에 [1] | TheMics | 2003.04.11 |
| PHP 혼자 공부하기 - 6 :: 연산자 [7] | 행복한고니 | 2003.04.11 |
| PHP 혼자 공부하기 - 5 :: 변수 [4] | 행복한고니 | 2003.04.10 |
| PHP 혼자 공부하기 - 4 :: 미리 정의된 변수 [13] | 행복한고니 | 2003.04.09 |
| PHP 혼자 공부하기 - 3 :: 변수형 [8] | 행복한고니 | 2003.04.09 |
| PHP 혼자 공부하기 - 2 :: PHP의 시작 [9] | 행복한고니 | 2003.04.09 |
| PHP 혼자 공부하기 - 1 :: 준비물 [3] | 행복한고니 | 2003.04.09 |
| 개판 오분전 세션 - 7 [10] | 미친개 | 2003.04.08 |
정말 많은 도움 되고 있습니다. 정말 감사합니다.^^